| XML |
 |
 |
 |
| SOFTWARE - Programación | ||||||||||||||||||||||||||||||||||||||||||
| Osteguna, 2009(e)ko otsaila(r)en 12-(e)an 09:49etan | ||||||||||||||||||||||||||||||||||||||||||
|
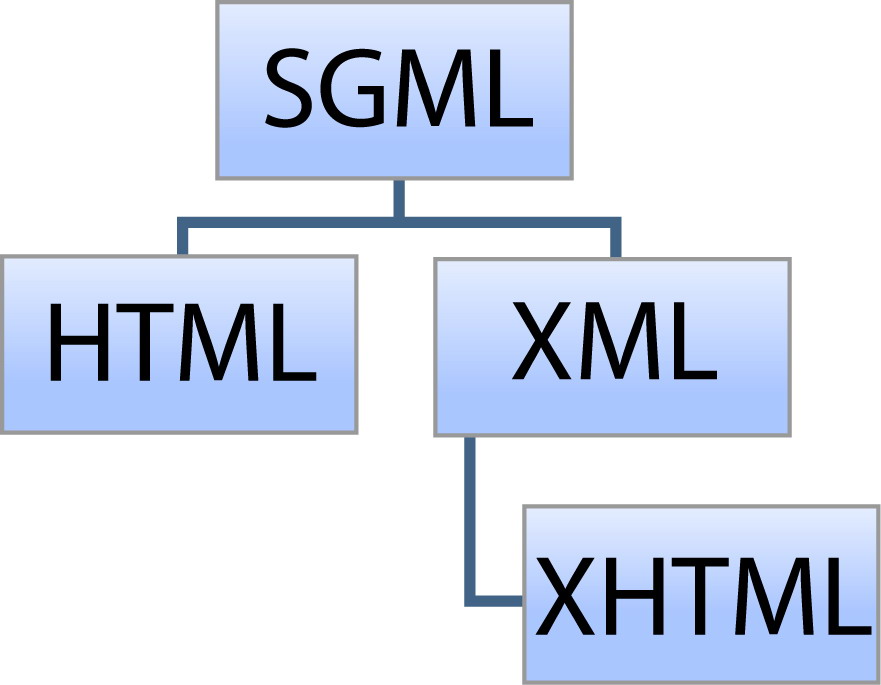
There are no translations available. Descubre en este artículo, todo lo referente a este lenguaje de descripción de documentos... IntroducciónXML significa en Inglés eXtensible Markup Language y es un lenguaje de descripción de documentos que no incluye ninguna información relativa al diseño de éstos. HTML (HyperText Markup Language) es el lenguaje de marcas (etiquetas) mas conocido y utilizado para la creación de páginas web que permite la navegación tipo hipertexto. Pero XML es mas que un lenguaje, es un metalenguaje que permite definir otros lenguajes de marcas con objetivos diferentes. Por ese motivo se le llama 'eXtensible'. Por lo tanto, XML no es realmente un lenguaje en particular, sino una manera de definir lenguajes específicos. Un ejemplo de lenguaje que usa XML para su definición es XHTML (eXtensible, Hypertext Markup Language), nueva versión de HTML que cumple la especificación SGML y cuyo objetivo es sustituirlo como estándar de páginas web. XML aparece en 1997 como un subconjunto de SGML (Structured Generalized Markup Language, ISO 8879), lenguaje que permite especificar las reglas de etiquetado de documentos. XML es algo así como SGML simplificado. Una aplicación no necesita comprender SGML completo para interpretar un documento XML. Los editores SGML, sin embargo, pueden comprender XML.
Como ejemplo práctico de la utilidad de XML podemos decir que muchos portales y sitios de noticias están basados en XML, ya que su utilización permite estructurar la información y luego aplicar transformaciones para presentar dicha información. Es decir, la información estará almacenada en la base de datos del sitio, se exporta a XML y a partir de aquí se aplican las transformaciones necesarias para presentarla. Otro ejemplo de utilización es la suite ofimática OpenOffice, basada totalmente en la utilización del formato XML. Es decir, todos los archivos se guardan en formato XML. Por lo tanto y como resumen: ¿Qué es XML?
¿Para qué sirve XML? Características de XML.Las características mas importantes de XML son las siguientes:
Como vemos por las características descritas, las ventajas de la utilización del formato XML son muchas. Pero también tiene sus inconvenientes:
Leyendas sobre XMLXML es una extensión de HTML → Falso
XML puede ser manejado directamente por el navegador web → Falso
Tecnologías XMLAsociado a XML existe la:
DTD (Document Type Definition): archivo que almacena la definición formal de un tipo de documento y especifica su estructura lógica. En general la utilización del DTD es opcional aunque conveniente. En función de si se utiliza o no DTD los documentos serán 'válidos' o sólo 'bien formados'. XSL (eXtensible Stylesheet Language): establece el lenguaje de estilo del documento XML permitiendo modificar el aspecto del mismo. Permite la visualización de tablas, tipos y tamaños de letra diferentes. Es más potente que las hojas de estilo CSS. Utiliza:
Docbook: es un lenguaje de creación de textos electrónicos que dispone de DTD propia y se utiliza sobre todo para generar documentación técnica relacionada con aplicaciones informáticas. El standar de Docbook es mantenido y actualizado por el grupo OASIS. Documentos XMLLos documentos XML tienen una estructura lógica y una física.
Ambas estructuras, lógica y física deben encajarse correctamente. Veamos un primer ejemplo de documento XML y su estructura básica. Para su creación necesitamos un editor de texto, tipo Bloc de Notas de Windows o gedit de GNU/Linux. En cualquiera de los dos editores introducir el código siguiente:
Un capítulo en la realidad deberá tener mas contenido organizado en secciones. Esto es sólo un ejemplo muy concreto y en él observamos una serie de etiquetas e informaciones importantes de la estructura lógica que vamos a describir : 1ª línea: Es el prólogo del documento y en él se establece que es xml mediante la etiqueta <?xml ........?>. Dentro de esta etiqueta debe ir todo en minúsculas. 'version' indica la versión de xml actual utilizada, que es la 1.0. 'encoding' indica el conjunto de caracteres utilizado. En el ejemplo es utf-8 (unicode) que representa el conjunto de caracteres universal. Otros ejemplos de prólogos son los siguientes:
Identifica el tipo de documento, es decir el DTD utilizado. En el ejemplo se trata de un capítulo de un libro (book) utilizando la DTD Docbook4 que es pública (PUBLIC) es decir, con validez en cualquier sistema. 4ª línea y siguientes: Constituyen el cuerpo del documento y en él se podrán utilizar aquellas etiquetas disponibles desde el DTD indicado, o creadas por el usuario e incluidas correctamente en el DTD. En nuestro caso utilizamos la etiqueta <chapter></chapter> indicando que es un capítulo de un libro y dentro de él definimos diferentes niveles de secciones (<sect1></sect1>; <sect2></sect2>;...). Los contenidos del capítulo propiamente son párrafos (<para></para>). Hay que tener en cuenta que XML diferencia entre mayúsculas y minúsculas. Por ejemplo, XML tratará como etiquetas diferentes <sect1> y<Sect1>. EtiquetasExisten seis tipos de etiquetas: elementos, referencias a entidades, comentarios, instrucciones de procesamiento, secciones de datos y declaraciones de tipo de documento.
DTDLa definición de tipo de documento (DTD) es una descripción de estructura y sintaxis de un documento XML5. Una DTD describe:
Una DTD no es mas que un archivo de texto con extensión .dtd cuyo contenido es un elemento raíz o tipo y una descripción de todos los elementos que intervienen en dicho elemento raíz. Por ejemplo, para el caso del capítulo del libro se está haciendo uso de la DTD docbookx.dtd cuyo contenido está predefinido y es algo complejo. Pero un usuario puede definir su propia DTD. Supongamos que queremos crear una DTD para el tipo libro. Se asume que un libro tiene título, autor y una serie de capítulos a su vez con título y texto. La DTD libro.dtd podría ser:
donde:
define la etiqueta libro que es el elemento raíz. Esta definición comienza con <!ELEMENT .... Los nombres encerrados entre paréntesis indican que un libro consta de un autor, un titulo y uno o más capitulo (+). Forman un grupo de elementos separados sólo por (,) si se quiere indicar que deben aparecer todos ellos de forma obligatoria (y). Si se quiere indicar opcionalidad deben ir separados por (|). Si un elemento aparece con (?) indica que puede aparecer o no ese dato en el libro. El orden en el que aparecen los elementos establece su orden de utilización en el documento.
La línea anterior define la etiqueta capitulo con el elemento titulocap y texto. El resto de líneas definen los elementos de forma ordenada, indicando entre paréntesis (#PCDATA) que significa que el elemento puede contener datos de tipo carácter (Parser Character Data).
Es posible también utilizar en la definición de los elementos el carácter (*) que indica que éste elemento se puede utilizar todas las veces que se quiera, pero no es obligatorio. Se diferencia del símbolo (+) en que éste indica que, al menos, se ha de utilizar una o varias veces6. El siguiente paso es referenciar el uso de nuestra DTD en el código XML. Esto se hace en la línea de identificación de tipo de documento:
En ella se indica cuál es el elemento raíz (libro) del documento y con SYSTEM se indica que la validez de la DTD es sólo local, para nuestros documentos XML. libro.dtd es la DTD propiamente y debe incluirse, en general, con el path absoluto. Ahora creamos un pequeño documento XML que utilice la DTD libro.dtd:
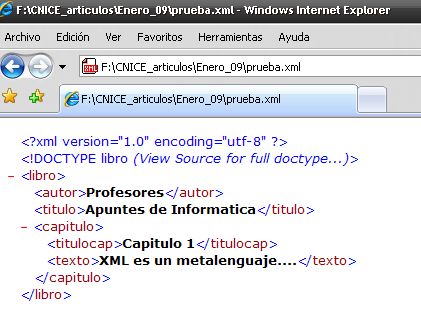
¿Qué aspecto tendría el documento escrito utilizando nuestra DTD? En el caso de utilizar el navegador Internet Explorer:
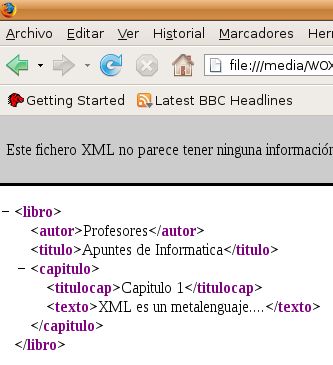
En el caso de abrir el archivo desde el navegador Mozilla Firefox:
Este sería el caso de utilización de una DTD externa, es decir, guardada en un archivo .dtd. También se puede incluir directamente la DTD en el archivo .xml de la siguiente forma:
En general, si se quiere reutilizar la DTD es preferible hacerla externa. En el ejemplo del libro es posible tener el documento XML distribuido en varios archivos:
Lógicamente habría que redefinir el elemento raíz para dar cabida a los diferentes capítulos del libro e incorporar las nuevas etiquetas <cabecera></cabecera> y <cuerpo></cuerpo>. En este ejemplo aparece el término ENTITY ... y ¿qué son las entidades? EntidadesLas entidades son tipos de objetos que permiten representar caracteres que no se pueden incluir como texto, como caracteres especiales, etc. Siguen la sintaxis siguiente: <!ENTITY identificador "valor"> Pero, además, las entidades permiten que, al ser referenciadas, el procesador reemplaze el identificador por el contenido asignado como valor, que puede incluir marcado. Por ejemplo, si en un documento necesitamos hacer referencia a menudo a un enlace, como http://www.isftic.mepsyd.es/ podemos crear un entidad cuyo identificador sea isftic y su valor sea la propia referencia en HTML (etiqueta <a></<a>, con atributo href). La entidad quedaría definida de la forma siguiente:
Si necesitemos incluir muchas veces este enlace en un documento, en vez de escribir cada vez la estructura <a></a>, podemos referenciar la entidad creada de la forma &isftic;, que funcionará como abreviatura de la expresión completa. Cada vez que en el texto escribamos &isftic; se sustituirá por el link <a href='http://www.isftic.mepsyd.es>isftic</a>. Otro ejemplo de utilización de entidades es el ejemplo anterior en el que conseguimos incluir el contenido de un archivo completo a través de la entidad. La sintaxis en este caso es:
Por ejemplo, si nuestro libro tiene un índice y dos capítulos definimos tres entidades y las referenciamos de la forma siguiente:
En este caso las referencias &indice, &capitulo1 y &capitulo2 se sustituirán por los archivos .xml correspondientes. Validación de documentos XMLEn general un documento es válido si sigue el patrón establecido por la DTD. Si, por ejemplo, no establecemos DTD y se utiliza en vez de<capitulo>, <capitulos>, el archivo seguirá estando disponible y podrá estar bien formado, pero no será válido. Los programas que se encargan de comprobar o validar el código xml en función de las reglas establecidas se llaman parsers validadores (analizador sintáctico). Existen muchos disponibles tanto para Windows como para GNU/Linux. Si se decide no utilizar una DTD entonces se podrán generar documentos 'bien formados' pero no 'válidos'. Un documento decimos que está 'bien formado' cuando:
Los documentos 'válidos' además de estar 'bien formados' deben cumplir las reglas establecidas en la DTD. El proceso de validación realizada por un parser validador comprueba:
Aunque la situación ideal es utilizar un validador integrado en el editor XML es posible que, en determinadas circunstancias, interese disponer de algún programa validador específico. Por ejemplo, en el caso de necesitar validar XML directamente desde Internet se puede acceder a sitios concretos que realizarán esta validación en línea. Es el caso de la web http://validator.w3.org. El validador disponible en http://www.stg.brown.edu/service/xmlvalid/ permite validar también pequeños documentos XML tanto si están o no en la web. Editores XMLUna vez conocida la estructura de un documento XML y vistos algunos ejemplos vamos a utilizar editores XML específicos que facilitan la tarea de edición. Los editores XML se pueden agrupar en:
Editores de texto adaptados a XMLLa funcionalidad básica que debe ofrecer un editor de texto para XML es la siguiente:
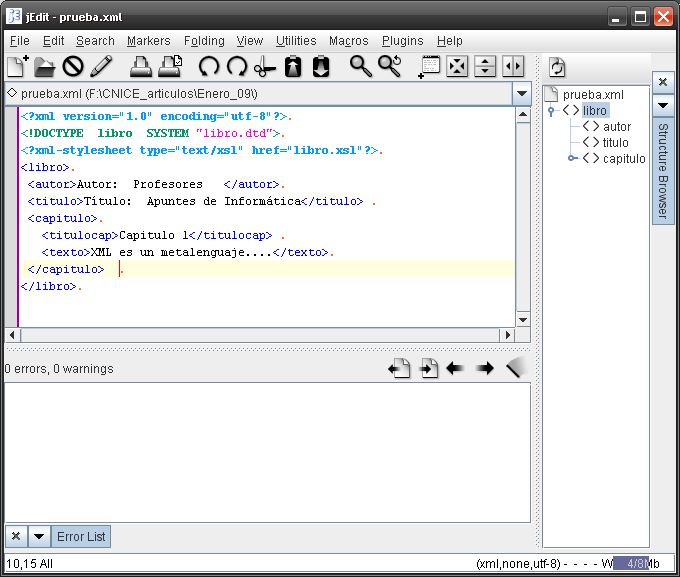
Editor jEdit Dentro de este grupo el editor mas conocido es jEdit que está escrito en Java y diseñado como entorno de desarrollo de programas. Tiene licencia GPL. La web oficial del proyecto es http://www.jedit.org. Para trabajar con jEdit se debe disponer del entorno Java Runtime, descargable desde http://www.java.com/es/ (Descarga gratuita de Java). A continuación hay que descargar e instalar la última versión estable de jEdit desde su página oficial. En el momento de escribir el artículo es la 4.2. Descargar y ejecutar jEdit. Para ser utilizado como editor de XML requiere la instalación de algunos plugins específicos. Describimos su configuración desde una instalación hecha en Windows XP.
Plugins → Plugins Manager → Install → Download options Actualizar la lista de plugins disponibles y buscar e instalar uno llamado 'XML'. Este plugin arrastra a otros necesarios para trabajar con documentos XML. Indicar el mirror desde el cual se realiza la descarga. Instalar también los plugins Error List y SideKick.
Herramientas de edición gráficaLas herramientas de edición gráfica no muestran las marcas XML y representan el documento utilizando estructuras en árbol o cajas anidadas, texto con colores, etc. Existen muchos editores XML gráficos y en general todos ellos permiten verificar que el documento está 'bien formado' y es 'válido' para una DTD. Los siguientes son algunos de los editores gráficos XML más importantes:
Como ejemplo de utilización de un editor gráfico descargamos el archivo MissionKitXMLDevEnt2008.exe (xmlspy) y lo instalamos en Windows XP aceptando las opciones por defecto. Como es una versión de prueba habrá que solicitar la clave de acceso a la herramienta. La recibimos por correo y con ella podemos terminar la instalación. En realidad lo que estamos descargando es toda una suite XML que incluye varias herramientas de las cuales nosotros utilizaremos xmlspy y stylevision. La primera herramienta es el editor gráfico XML y la segunda se utiliza para el diseño de hojas de estilo.
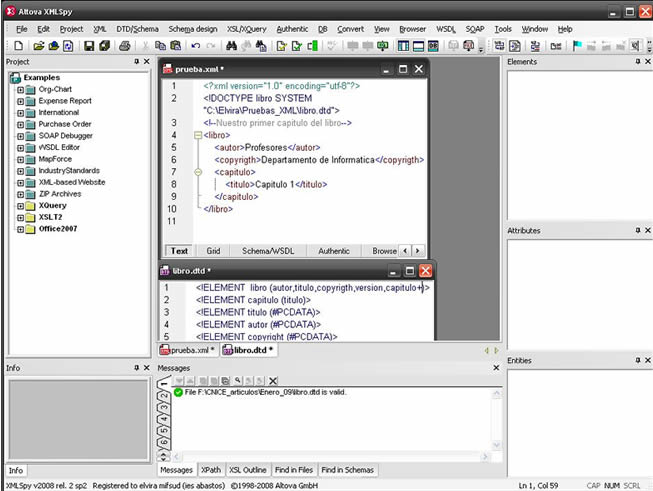
El aspecto de la interfaz mostrada es el siguiente: Si abrimos el ejemplo del libro nuestro comprobamos que nos indica que es válido. Si no localiza el DTD habrá que indicar el path completo.
Como puede observarse existe un gran número de opciones donde elegir, tanto en editores de texto como editores gráficos, libres y de pago. La elección es personal en función de las necesidades y preferencias. Ejemplos de utilización de XMLUn ejemplo clásico de documento XML es el relativo a los datos de un mensaje de correo electrónico. Suponemos definida una DTD propia correo.dtd cuya referencia incluimos en el documento:
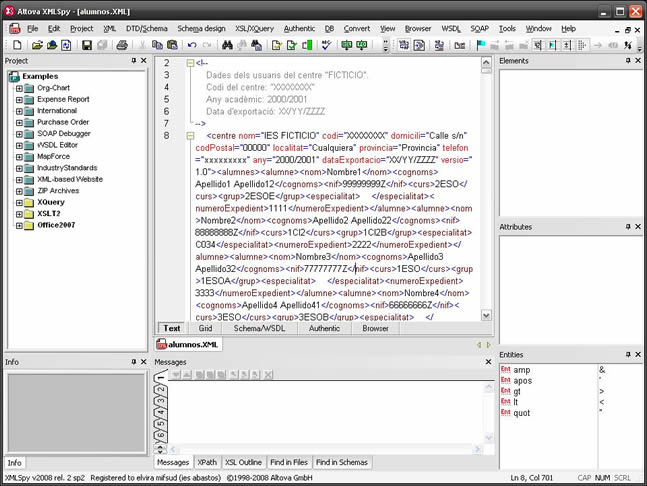
Otro ejemplo típico puede ser el archivo XML generado por la exportación desde una BBDD para ser importado por otra BBDD. En este ejemplo se trata de los datos de la matrícula de un centro hipotético7 que se necesitan para dar de alta, de forma automática en otra aplicación, a dichos alumnos. El archivo se muestra desde la interfaz de xmlspy.
Utilización de CSSEl objetivo de este punto es aprender a dar formato a los documentos XML para su correcta visualización en un navegador. Para ello utilizamos CSS. Utilizaremos como ejemplo base el del libro.
El elemento raíz es libro y contiene las etiquetas titulo, autor y capitulo.
En términos CSS las etiquetas libro y titulo se llaman selectores y todos los atributos asignados a la presentación de los datos contenidos en las etiquetas correspondientes deben ir entre llaves. En el caso de que dos o mas etiquetas requieran el mismo estilo indicar de la forma:
En este caso hemos añadido un color para el texto. De esta forma podemos establecer el estilo de cada una de las etiquetas y para ello disponemos de una gama de atributos aplicables cuya descripción no son objeto de este artículo y que pueden consultarse en diferentes webs. En el caso de que el documento utilice una DTD, el enlace a la hoja de estilos utilizada debe colocarse siempre debajo de dicha referencia:
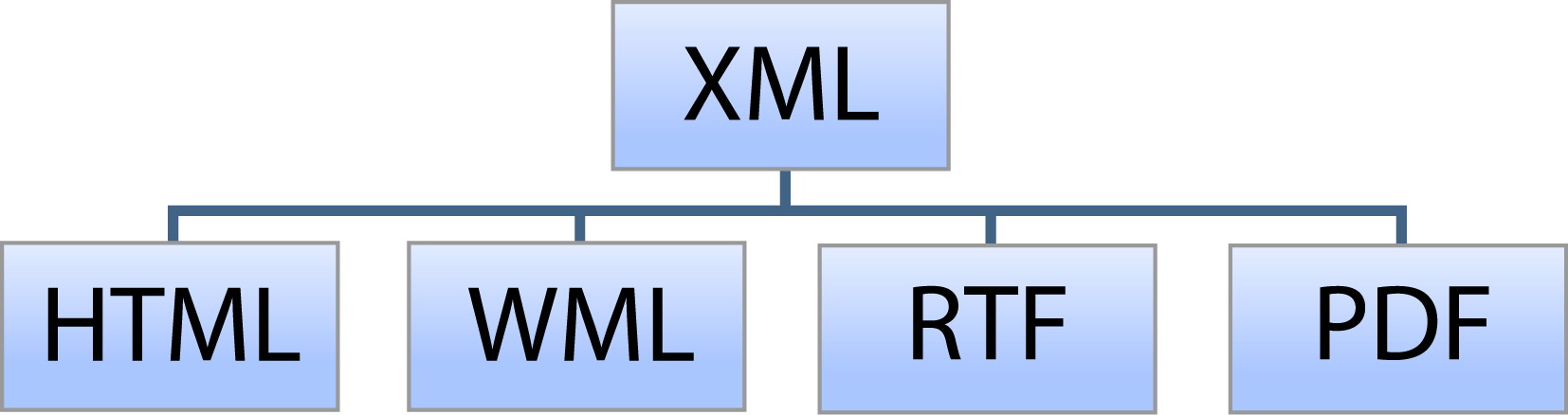
Utilización de XSLAunque no hemos entrado con detalle en CSS si que podemos decir que sus posibilidades son limitadas y que para visualizar los documentos en el navegador como realmente queremos a menudo CSS se queda corto. En estos casos la solución suele ser utilizar conjuntamente CSS y HTML, para lo cual necesitamos utilizar otro estándar llamado XSL (eXtendible Stylesheet Languaje, Lenguaje extensible de hojas de estilo) que, desde 2001 es la recomendación oficial de la tripleW (World Wide Web Consortium). Dentro de este estándar nos interesa, especialmente para aplicar transformaciones (formatear) a documentos XML, el subconjunto de dicha especificación, llamado XSLT. XSLT nos permitirá transformar el documento XML a HTML. También transforma XML a WML (Wireless Markup Language) para móviles con WAP; a SVG (Scalable Vector Graphics) y utilizando XSL-FO (XSL FormattingObjects ) a PDF. Para ello abrimos el documento XML desde el editor xmlspy sobre él hemos de generar una salida en XHTML.
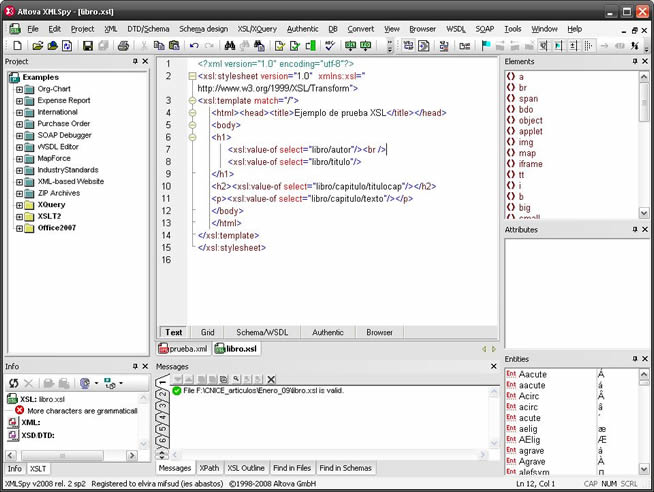
El archivo de estilo generado libro.xsl es el que se muestra abajo.
Donde: 1ª línea: parte obligatoria de xml. 2ª línea: <xsl:stylesheet.... es elemento raíz del archivo .xsl que se cierra en la línea 15. xmlns:xsl es un atributo del elemento raíz donde xmlns es el espacio de nombres8. 3ª línea: <xsl:template.... hace referencia a la plantilla utilizada en la transformación. En el caso de este ejemplo tan sencillo se hace referencia al elemento raíz del documento XML. 4-13 líneas: es un esqueleto HTML típico y dentro de él incluimos sintaxis de XPath para indicar el camino a los elementos XML. 14-15 líneas: cierre de las etiquetas template y stylesheet. Para validar el documento libro.xsl pulsar F8. El código siguiente será el documento prueba.xml con la línea de estilo incluida (libro.xsl) y la referencia a la DTD:
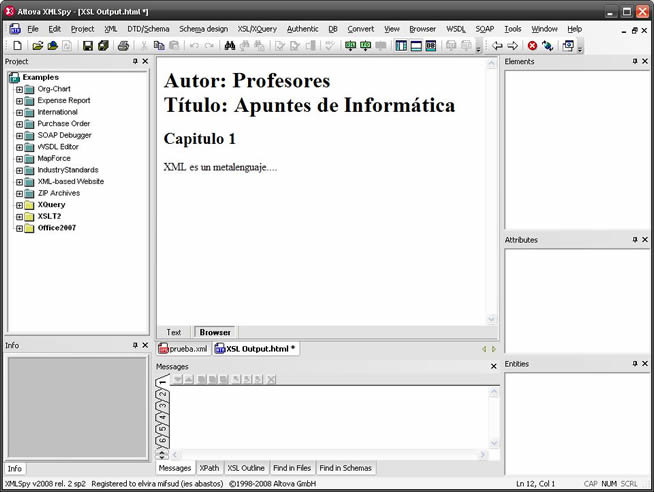
El aspecto que mostraría un navegador con el estilo asociado se obtiene pulsando F10 (XSL Transformation) es el siguiente:
Observar que para conseguir un salto de línea detrás de Profesores, se ha incluido en libro.xsl la etiqueta <br />. Desde un navegador como Firefox o Internet Explorer el aspecto sería el mismo. A partir de aquí se podrían ir añadiendo diferentes etiquetas HTML referentes a listas, tablas, etc, además de colores y otros estilos que se necesiten aplicar al documento. ConclusiónEn realidad con este artículo sobre XML sólo hemos abierto una puerta al mundo de los metalenguajes de marcas. Hay vida mas allá del HTML y es interesante conocer estos estándares que nos permiten crear archivos entendibles por humanos y procesables por las máquinas independientemente de la plataforma. Pero estamos hablando de estándares del año 1997, es decir diez años en los que han surgido nuevas propuestas que están dejando en evidencia algunos de los problemas del XML. Entre ellos cabe destacar el hecho de que el código XML no es directamente utilizable desde ningún lenguaje de programación. Sabemos que XML fue una revolución en sus orígenes ya que puso orden dentro del mundo de los lenguajes de marcas. Pero desde hace algún tiempo lenguajes como JSON están tirando fuerte ya que presentan todas las ventajas de XML y además es código directamente utilizable desde Javascript, por ejemplo. No sabemos ahora mismo cuál será el futuro de XML y si será desplazado por JSON. En este momento avanzan en paralelo, XML como generador de lenguajes ya establecido y de probada eficiencia y JSON con muy buenas perspectivas y resultados en su corta andadura.
|