| MONOGRÁFICO: Creación de una emisora de radio a través de Internet - Anexo II. Captura y Compresión del Sonido Digital |
 |
 |
 |
| Monográficos - Monográficos |
| Écrit par Javier Martín |
| Dimanche, 13 Juillet 2008 15:27 |
|
Page 7 sur 9
Anexo II. Captura y Compresión del Sonido DigitalCon la aparición del audio digital la adquisición y transmisión de audio ha cobrado una nueva dimensión que permite almacenar con calidades muy buenas ingentes cantidades de música en soportes relativamente pequeños. El secreto se encuentra en la compresión del audio, un sistema por el cual se puede minimizar el tamaño del archivo resultante en función de la calidad que se desee obtener. Antes de introducirnos en el mundo de la compresión del sonido hemos de explicar primero cómo conseguir que el audio, analógico por definición, pueda almacenarse digitalmente. Un proceso de transformación Analógica-Digital permite que el ordenador o el equipo digital- pueda manejar la información de audio. Para que nuestro oído reciba de nuevo el sonido existe otro proceso de conversión Digital-Analógico. La característica más importante de este proceso es el muestreo. Si disponemos de una señal de audio analógica continua en el tiempo-, podemos tomar muestras de la misma con un intervalo determinado frecuencia de muestreo- e ir almacenando el valor de la señal en ese punto. La siguiente figura resume mejor el procedimiento: la señal de audio analógica se muestra en rojo a lo largo del eje temporal, mientras que las muestras capturadas toman los valores de esa señal en distintos instantes de tiempo.
El teorema de Nyquist marca las limitaciones del muestreo: sólo será posible recuperar exactamente la forma de onda si la frecuencia de muestreo es como mínimo el doble de la frecuencia de la componente de mayor frecuencia. Puesto que la frecuencia más alta que puede percibir el oído humano está cercana a los 20kHz, la frecuencia de muestreo de 44,1KHz utilizada por los reproductores de audio CD resulta más que suficiente. Otro parámetro importante es el tamaño en bits con el que se codifica cada muestra. Valores típicos de este parámetro son 8 bits con un rango dinámico de hasta 50dB- y 16 bits hasta 90dB-. El oído humano es muy sensible a este parámetro, puesto que su respuesta es logarítmica, en dB. Esta unidad, no lineal, representa la relación entre dos magnitudes acústicas. El umbral de audición se ha establecido en 0dB, mientras que el umbral del dolor se encuentra a 140dB. Si bien el oído no escucha de la misma forma a todas las frecuencias, es necesario conocer que, a mayor intensidad sonora, menos tiempo podremos estar escuchando ese sonido. En todo soporte audiovisual hay dos tipos de componentes de señal: la información que es nueva o impredecible y aquella que puede ser anticipada. Los componentes nuevos, llamados entrópicos, son los que contienen la verdadera información de la señal, mientras que la información redundante no es esencial y puede empaquetarse o eliminarse sin que exista una pérdida significativa mediante procedimientos de compresión. Las técnicas de compresión aplicadas sobre audio digital permiten reducir la información del mismo para su posterior almacenaje o transmisión. Aunque generalmente se utilizan técnicas de codificación sin pérdidas, que permiten que recuperar la información redundante enviando sólo la información entrópica, para lograr grandes tasas de compresión se hace necesario reducir la información enviada, utilizando técnicas de codificación con pérdidas. Dentro de este último grupo se encuentra la compresión Mp3 Las técnicas de compresión de audio hacen un estudio exhaustivo de cómo funciona el oído humano en combinación con el cerebro, de forma que la información que se elimine sea lo más imperceptible posible para el oído. Entramos, por tanto, en el campo de la psicoacústica. Según estudiaron Robinson y Dadson en 1956, el oído sólo puede captar sonidos dentro de determinado rango de frecuencias e intensidades. La siguiente figura muestra las curvas características de percepción de sonido por el oído humano, con la intensidad de los sonidos (eje vertical) y su valor en frecuencia (eje horizontal). En dichas curvas, denominadas isófonas, cada valor en la curva representa la intensidad equivalente de un tono de 1Khz a la frecuencia e intensidad tratadas.
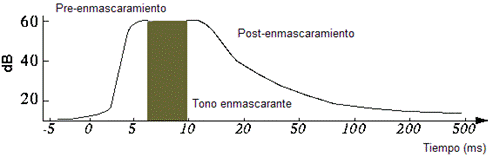
La primera conclusión que podemos avanzar es que todo sonido por debajo de la curva inferior será inaudible para el oído humano. Así, si eliminamos la información de intensidad inferior a este umbral el oído no notará la diferencia. Puesto que el oído humano medio sólo escucha en un rango de frecuencias de 20Hz-20KHz, el segundo sistema que se utiliza es eliminar las frecuencias que se salgan de este rango. Además, existe un fenómeno curioso, llamado enmascaramiento, que permite comprimir mucho más la información. Si dos estímulos sonoros de diferente intensidad llegan a nuestro oído de manera cercana en el tiempo, el tono más intenso puede llegar a enmascarar al débil, de forma que resulte inaudible. Este hecho, al contrario de lo que podría parecer, no ocurre solo cuando el tono débil suena después del intenso (post-enmascaramiento), sino también cuando el impulso sonoro de menor amplitud suena antes (pre-enmascaramiento).
Enmascaramiento Temporal El fenómeno de enmascaramiento no se da sólo entre dos tonos separados mínimamente en el tiempo. Cuando el oído está expuesto simultáneamente a dos o más sonidos de distinta frecuencia existe la posibilidad de que uno de ellos enmascare a los demás, resultando, asimismo, inaudibles. Se trata del enmascaramiento frecuencial. Así, en la siguiente imagen podemos comprobar cómo se modifica la curva isófona del oído para un tono de 1KHz, mostrando cómo se enmascararían las frecuencias que sonaran simultáneamente.
Enmascaramiento Frecuencia Una aplicación directa de este proceso consiste en estimar qué sonidos, en frecuencia y tiempo, serán enmascarados por otros, de forma que puedan codificarse con menos bits o, incluso, eliminarse, puesto que serán inaudibles aunque se transmitan. Los formatos de compresión de audio, como el Mp3, pueden utilizar este tipo de técnicas para conseguir que el archivo tenga un tamaño mucho menor sin perder una calidad de sonido apreciable. |